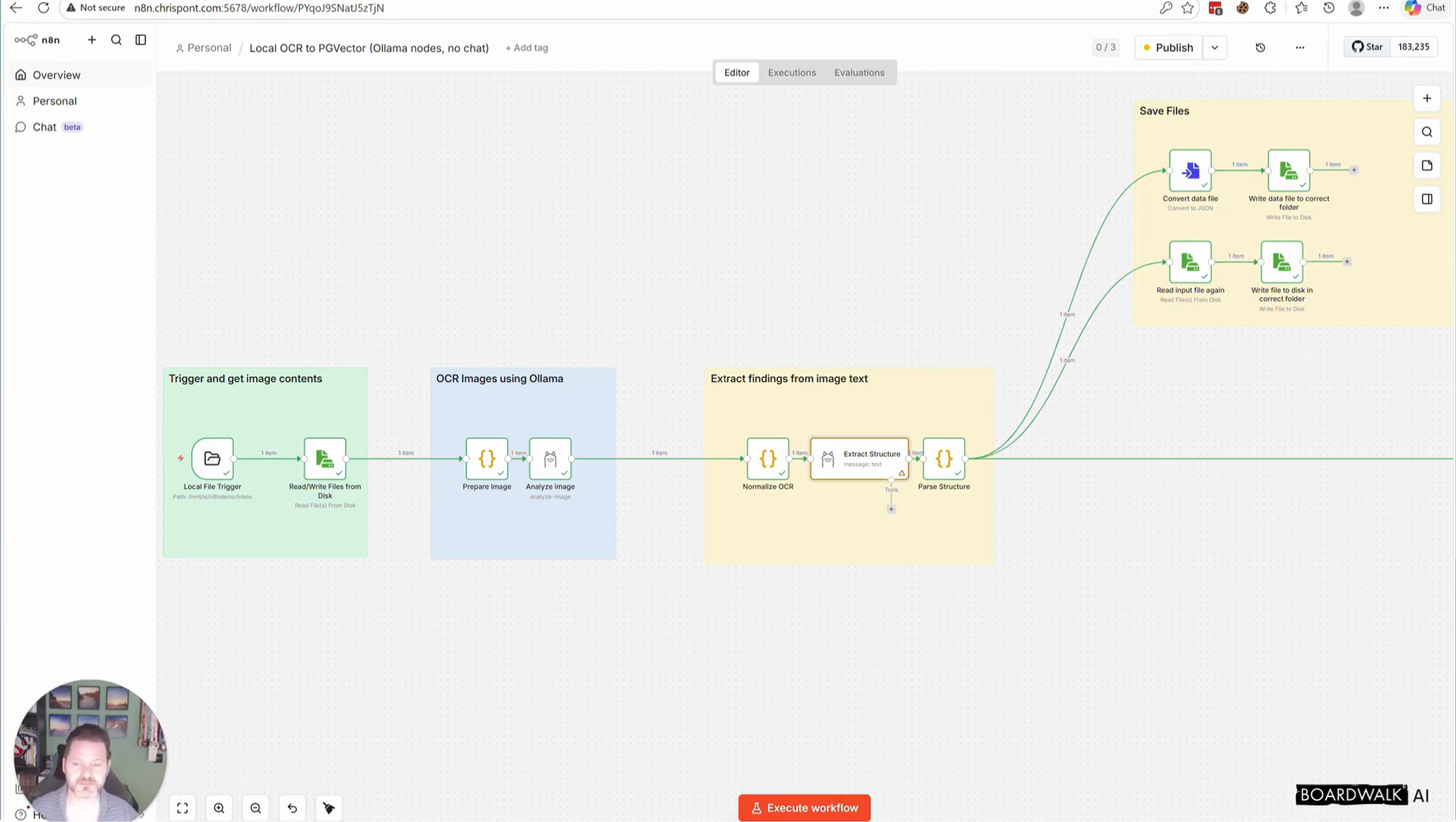
A lot of AI is presented as if the model itself is the product. In reality, the value often comes from the underlying data, how it is prepared, and how effectively the system retrieves the right information at the right time.
That’s what I’ve been building with a hyper-local AI service focused on Ipswich. I wanted to bring together local information from different sources, structure it, enrich it, and make it usable through search and chat. That includes public web content, local news, council updates, football club announcements, planning records, and PDF documents that would normally sit as static files with very little intelligence attached.

One of the most useful parts of the project has been working with planning PDFs. Rather than simply storing these documents, the service downloads them, extracts key details, and turns them into structured records. It then goes further by visiting related web pages, pulling out extra context such as postcodes, and converting that into latitude and longitude. That means the documents are no longer just searchable by text. They can also be searched by location.
So instead of asking for all planning updates, you can focus on activity within a specific radius of an area.
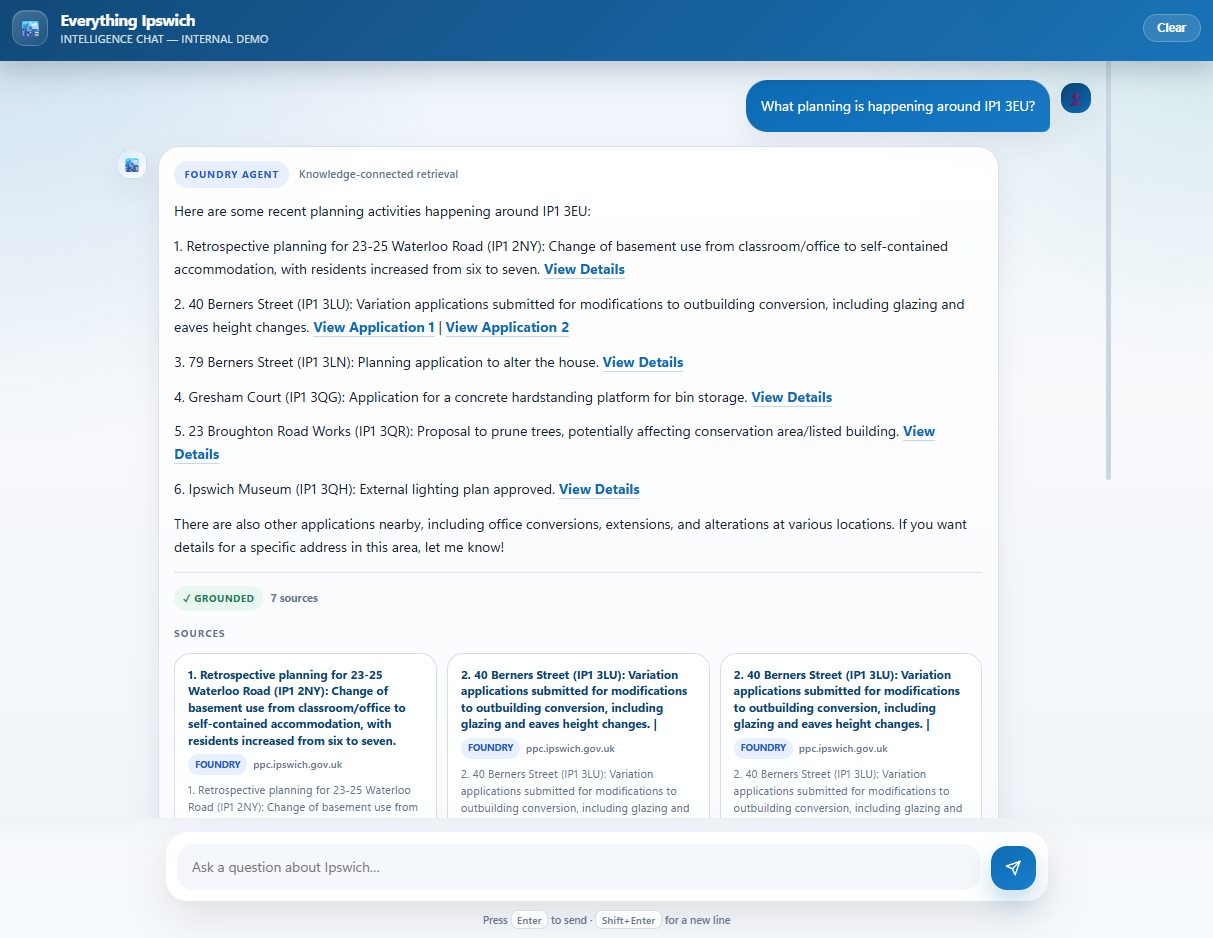
This is important because many modern AI systems rely on RAG (Retrieval Augmented Generation). In simple terms, that means the AI answers questions based on what a search layer can retrieve. If the search is generic, the answers will be generic too. If the search is built on enriched local information, the answers become much more useful.
That is where a hyper-local approach really worked. A general AI model may know broad facts, but it is unlikely to understand the latest planning applications near a postcode, recent council decisions, local developments, ITFC news, and how those things connect to one another. By building a stronger retrieval layer, you give the AI much better information to work from.
I am also using my local AI setup for summarisation and categorisation, which keeps a significant part of the enrichment process local. That helps reduce token usage and keeps cloud costs under control. Not by a huge amount, but every little helps! I think this is a practical pattern that more businesses will adopt as AI moves from experimentation into real operating models.
On the Azure side, Azure AI Search provides the retrieval backbone, including vector search for semantic matching. I am also using Azure Foundry to orchestrate grounded responses and tool use, including a geo-search function that can query content by latitude, longitude and radius.
.png)
The result is not just a chatbot surfaced in a browser or Teams. It is a locally aware intelligence layer. Ipswich is the current focus, but the same pattern could be applied much more widely. Many organisations are sitting on legacy documents, reports and records that are technically stored but not truly usable. With the right architecture, that content can be enriched, indexed, and turned into something people can actually explore, search and ask questions against.
That is the part of AI I find most interesting - not generic assistants, but real systems that take messy information and turn it into something useful, grounded and commercially relevant.